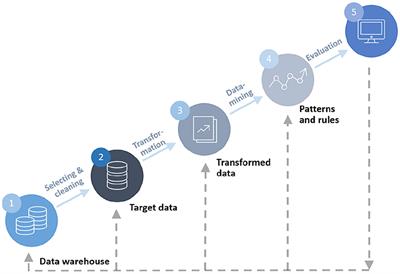
Survey data cleaning is the process of removing errors and inconsistencies from collected survey data. It ensures the accuracy and reliability of the data for further analysis.
We will explore the importance of survey data cleaning and discuss various techniques and best practices to achieve it effectively. Proper data cleaning is vital as it helps in minimizing biased results, improving data quality, and increasing the validity of the analysis.

It involves tasks such as handling missing data, identifying and correcting outliers, standardizing variables, and checking data integrity. By following these steps, researchers can ensure that their survey data is clean and ready for meaningful analysis.
The Importance Of Survey Data Cleaning

Survey data cleaning is vital for accurate and reliable results. Removing errors and inconsistencies ensures the quality of the data, allowing researchers to draw meaningful insights and make informed decisions based on trustworthy information.
Accurate and reliable survey results are crucial for making informed decisions and driving successful business strategies. However, the presence of dirty data can negatively impact the validity and reliability of survey findings. This is where the process of survey data cleaning becomes essential.
By eliminating errors, inconsistencies, and inaccuracies from survey data, researchers can ensure that the insights derived are accurate, trustworthy, and actionable. Let’s delve into the impact of dirty data on survey results and explore the benefits of clean data for obtaining accurate insights.
Impact Of Dirty Data On Survey Results:
- Inaccurate analysis: Dirty data can lead to flawed analysis, misleading conclusions, and erroneous insights. It can introduce bias, distort trends, and undermine the reliability of survey findings.
- Misinformed decision-making: Relying on dirty data may result in misguided business strategies and poor decision-making. When data is tainted with errors, organizations risk allocating resources and making investments based on inaccurate information.
- Reduced credibility: Survey results derived from dirty data can damage the reputation and credibility of research studies, making it challenging to gain trust from stakeholders and decision-makers.
- Wasted time and resources: Dealing with dirty data requires significant time and effort. Without proper data cleaning, researchers may need to repeat surveys or expend resources on correcting errors, leading to inefficient processes and delays in obtaining insights.
Benefits Of Clean Data For Accurate Insights:
- Enhanced data quality: Clean data ensures that survey responses are accurate, consistent, and reliable. With clean data, researchers can have confidence in the quality of the information they analyze.
- Reliable trend analysis: By eliminating inconsistencies and errors, clean data allows for precise trend analysis. Researchers can identify patterns, track shifts, and gain valuable insights into respondent behaviors over time.
- Trustworthy decision-making: Clean data enables organizations to make well-informed decisions based on reliable information. Accurate insights derived from clean data can guide strategic planning and drive successful business outcomes.
- Increased confidence in survey findings: Through data cleaning, researchers can strengthen the validity of their survey findings. This increases the confidence placed in these findings by stakeholders, supporting the adoption of insights for decision-making purposes.
Survey data cleaning is essential for obtaining accurate and trustworthy insights. Dirty data can compromise the validity and reliability of survey results, leading to misinformed decision-making and wasted resources. On the other hand, clean data enhances data quality, supports reliable trend analysis, enables informed decision-making, and increases confidence in survey findings.
By prioritizing survey data cleaning, organizations can ensure that they are equipped with accurate and actionable insights for driving their success.
Step 1: Preparing For Data Cleaning
To prepare for data cleaning in survey research, it is crucial to follow a systematic approach. This involves organizing and categorizing the collected data, identifying any inconsistencies or errors, and selecting appropriate tools for cleaning and validation. By following these steps, you can ensure reliable and accurate survey data.
Understanding The Survey Design And Objectives
Before diving into the data cleaning process, it is crucial to have a clear understanding of the survey design and objectives. This step lays the foundation for accurate and meaningful analysis of the survey data. Here are some key points to consider:
- Identify the target population: Determine the specific group of individuals the survey aims to represent. This could be customers, employees, or a specific demographic segment.
- Define the survey objectives: Clearly define what you intend to achieve with the survey. Are you looking to gather customer feedback, measure employee satisfaction, or collect market insights? Understanding the objectives helps in identifying relevant data points.
- Recognize survey type: Different surveys follow different methodologies. Whether it’s a cross-sectional survey, longitudinal study, or comparative analysis, understanding the survey type helps in interpreting the data accurately.
- Assess sampling methods: Take into account the approach used to select participants. Understanding the sampling methods employed helps identify potential biases in the data.
- Review questionnaire structure: Analyze the survey questions and response options to ensure they align with the research objectives. Check for any redundancies, ambiguities, or missing data points that may affect the cleaning process.
Overall, comprehending the survey design and objectives sets the stage for an effective data cleaning process, ensuring accurate insights and a solid foundation for subsequent analysis.
Identifying Potential Data Issues And Inconsistencies
Identifying and addressing data issues and inconsistencies is a critical aspect of the data cleaning process. By taking the time to identify potential problems early on, you can ensure the reliability and accuracy of your survey data. Here are some points to consider when conducting this step:
- Missing data: Determine if there are any missing values in the dataset. Missing data can impact the integrity and validity of the analysis. Identify the reason for missing values, whether it’s due to non-response or technical issues.
- Outliers: Look for data points that are significantly different from the rest of the data. Outliers can influence statistical analyses and should be carefully examined. Consider whether they are valid data points or potential errors.
- Data inconsistencies: Check for any inconsistencies across variables or respondents. Look for contradictions, unrealistic patterns, or illogical responses. Inconsistencies can occur due to respondent errors or data entry mistakes.
- Duplicate entries: Identify and remove any duplicate entries from the dataset. Duplicate entries can skew the results and create bias in the analysis. Ensure each record is unique and represents a distinct respondent.
- Data validation: Validate the data against predefined criteria and ranges. For example, check if numeric variables fall within an expected range or if categorical variables have valid response options.
By proactively identifying potential data issues and inconsistencies, you can improve data quality, minimize errors, and ensure the reliability of your survey results.
Step 2: Data Validation And Verification
In Step 2 of survey data cleaning, the process of data validation and verification is crucial. This ensures the accuracy and reliability of the collected data by identifying and correcting any errors or inconsistencies.
Once you have gathered survey data, the next crucial step is to ensure its completeness and accuracy through data validation and verification. This step involves checking data completeness and identifying and handling missing values. By conducting a thorough validation and verification process, you can have reliable and accurate data for analysis.
Here’s what you need to do:
Checking Data Completeness And Accuracy:
- Examine each survey response to make sure all required fields are filled out.
- Verify that the data aligns with the criteria established for your survey.
- Cross-check the data against any predefined ranges or options.
- Confirm that the data is consistent with the survey’s format and structure.
- Validate the data against any existing records or external sources.
Identifying And Handling Missing Values:
- Identify any missing values in the survey data.
- Evaluate the potential impact of missing values on your analysis.
- Decide on the most appropriate method for handling missing values, such as imputation or exclusion.
- Apply the chosen method to address missing values in a systematic and transparent manner.
- Document the process and any assumptions made during the handling of missing values.
By conducting data validation and verification, you can ensure the quality and reliability of your survey data. Checking completeness and accuracy as well as identifying and handling missing values are vital steps in preparing your data for analysis. Remember to document your processes and assumptions, as transparency is key in maintaining the integrity of your research.
Step 3: Removing Outliers And Anomalies
Step 3 of the survey data cleaning process involves identifying and removing outliers and anomalies from the data. This ensures that the data is accurate and reliable for analysis and decision-making.
Survey data cleaning involves several important steps to ensure the accuracy and reliability of your analysis. In , you need to focus on identifying and handling extreme values that can significantly impact your insights. Let’s delve into the process of dealing with outliers and anomalies.
Identifying And Handling Extreme Values:
- What are outliers? Outliers are data points that deviate significantly from other values in a dataset. They can arise due to measurement errors, data entry mistakes, or even genuine anomalies. Identifying and handling outliers is crucial to prevent them from skewing your analysis.
- Methods to identify outliers: There are several reliable approaches to detect outliers:
- Visual inspection: Plotting the data on graphs, such as box plots or scatter plots, can provide a visual indication of potential outliers.
- Statistical techniques: Utilize statistical methods like the Z-score or modified Z-score calculation to identify observations that fall beyond a certain threshold.
- Domain knowledge: Your expertise in the subject matter can help identify unrealistic values that might be outliers.
- Types of outliers: Outliers can be classified into two types:
- Univariate outliers: These are outliers that occur in a single variable or column. They can be identified by examining the distribution of the individual variable.
- Multivariate outliers: These outliers are detected by analyzing the relationship between multiple variables simultaneously. They can be identified through techniques like clustering or regression analysis.
- Handling outliers: Once outliers are recognized, you have several options to deal with them:
- Remove the outliers: If the outliers are deemed to be measurement errors or data entry mistakes, you can choose to exclude them from the dataset.
- Impute values: In cases where outliers are genuine anomalies, you can impute them with more representative values based on other data points.
- Transform the data: Sometimes, transforming the data using mathematical functions (e.g., logarithmic transformation) can mitigate the impact of outliers on the analysis.
- Document your actions: Remember to document the steps you take to identify and handle outliers. This ensures transparency and reproducibility of your analysis, allowing others to understand and validate your findings.
By effectively removing outliers and anomalies from your survey data, you can ensure that your insights are based on reliable and accurate information.
Step 4: Standardizing And Formatting Data
Step 4 of the survey data cleaning process involves the standardization and formatting of the collected data. This crucial step ensures consistency across all data points, making it easier to analyze and draw accurate conclusions from the survey results.
Ensuring Consistent Data Formats And Units:
In the process of survey data cleaning, one crucial step is standardizing and formatting the collected data. This step ensures that the data is consistent, making it easier to analyze and compare across different variables. Here’s how you can ensure consistent data formats and units:
- Convert data into a standardized format: Convert all data entries into a standardized format to eliminate any variations or discrepancies. This can include formatting numerical data consistently, such as ensuring that decimals and commas are in the correct places, or converting dates into a unified format.
- Check for units of measurement: Confirm that all variables have consistent units of measurement. For example, if you are collecting data on weight, ensure that all the weights are recorded in either kilograms or pounds, not a mix of the two. This step prevents any confusion or misinterpretation during data analysis.
- Resolve inconsistencies in variable labels and coding: It’s important to review the variable labels and coding used in the dataset. Check for any inconsistencies or errors that might affect the integrity of the data. Make sure that each variable’s label is clear and descriptive, avoiding any ambiguity that could lead to difficulties during the analysis phase.
- Create a standardized variable coding scheme: If there are inconsistencies in the coding of categorical variables, establish a standard coding scheme. Ensure that the codes assigned to different categories are consistently applied throughout the dataset. This practice allows for easier interpretation and comparison of the data.
- Address missing or erroneous data: While addressing inconsistent data formats and units, also identify missing or erroneous data. Cleanse the dataset by either removing or imputing missing values appropriately. This step helps to maintain the accuracy and integrity of the dataset.
By standardizing and formatting the data, you establish a solid foundation for further analysis. Ensuring consistent data formats and units makes the subsequent steps of data cleaning and analysis easier and more reliable.
Step 5: Data Deduplication And Record Matching
Data deduplication and record matching is a crucial step in survey data cleaning. By identifying and removing duplicate entries and matching similar records, this process ensures accurate and reliable data analysis.
Identifying And Removing Duplicate Responses:
Duplicate responses can occur when participants accidentally submit multiple entries or when the survey is accessed and completed multiple times by the same respondent. To ensure the accuracy of our data and eliminate any biases caused by duplicate entries, a thorough process of identifying and removing duplicate responses is crucial.
Here’s how we do it:
- Comparing participant IDs: We analyze each participant’s unique identifier, such as an email address or username, to identify if any duplicate entries have been made by the same individual.
- Matching responses based on specific criteria: By comparing responses across different survey questions, we can detect similarities or patterns that indicate potential duplicates.
- Utilizing timestamp information: We take into account the time and date stamps associated with each response to differentiate between multiple submissions from the same participant.
Matching Records For More Comprehensive Analysis:
Matching records allows us to combine similar responses and consolidate data for a more comprehensive analysis. This step is particularly useful when dealing with open-ended questions or when participants provide varied response formats. Here’s how we match records:
- Textual analysis: By applying various text analysis techniques, we identify and group together responses that convey similar sentiments or contain related keywords.
- Aggregating categorical data: We consolidate responses to categorical questions, such as age groups or preferences, to create meaningful groups for comparative analysis.
- Using record linkage algorithms: Advanced algorithms help us match records across different datasets, enabling the integration of information from multiple sources and ensuring a holistic analysis.
Matching records not only enhances the reliability and validity of our data, but it also allows us to uncover more nuanced insights that may not be evident when analyzing individual responses in isolation.
By following these data deduplication and record matching processes, we can confidently move forward with a clean and organized dataset, ready to unlock valuable insights for further analysis.
Step 6: Managing Data Integrity And Confidentiality
Learn how to effectively manage data integrity and confidentiality during the survey data cleaning process. Follow these step-by-step guidelines to ensure your data is accurate, secure, and free from errors.
In order to ensure the integrity and confidentiality of survey data, it is important to implement proper measures throughout the cleaning process. Protecting the privacy of survey respondents and maintaining the security of the data are crucial considerations. Here are some key steps to follow:
Protecting Survey Respondents’ Privacy And Confidentiality:
- Anonymize personal information: Remove any identifying details from the data to protect the privacy of respondents. This includes names, addresses, and any other sensitive information.
- Use secure storage: Store the data in a secure location, both physically and digitally, with restricted access to authorized personnel only.
- Obtain informed consent: Prior to data collection, explain the purpose of the survey and how the data will be used. Obtain consent from respondents to use their data while ensuring they understand their rights to refuse or withdraw participation.
- Compliance with regulations: Adhere to relevant data protection regulations such as GDPR or HIPAA, depending on the nature of the survey and data collected.
Ensuring Data Security And Integrity Throughout The Cleaning Process:
- Implement encryption methods: Encrypt the data during storage and transmission to prevent unauthorized access and maintain data integrity.
- Backup data regularly: Create backups of the original data to ensure data integrity is maintained in case of accidental loss or corruption during the cleaning process.
- Use reliable cleaning tools: Utilize trusted software and tools for data cleaning to minimize the risk of introducing errors or data breaches.
- Validate and verify data: Perform validation checks to ensure the accuracy and consistency of the data after cleaning. Compare it with the original data to identify any discrepancies.
- Document data cleaning steps: Keep a detailed record of all the steps taken during the cleaning process for future reference and to maintain transparency.
By following these practices, survey data can be effectively managed, ensuring both the confidentiality of respondents and the security and integrity of the data throughout the cleaning process.

Credit: www.rti.org
Step 7: Documentation And Version Control
Step 7 involves thorough documentation and version control, essential for survey data cleaning. This ensures accuracy, traceability, and organized management of the data throughout the cleaning process.
Keeping Track Of Data Cleaning Processes And Changes
When it comes to survey data cleaning, it’s crucial to have proper documentation and version control in place. This ensures transparency, reproducibility, and facilitates collaboration among team members. By keeping track of data cleaning processes and changes, you can easily troubleshoot issues, maintain data integrity, and provide evidence for the decisions made during the cleaning process.
Here are some key points to consider:
- Git repository: Set up a Git repository to track all changes made to the dataset. Git is a version control system that allows you to store different versions of your data and track modifications over time. It provides the ability to revert to previous versions, view changes made by different team members, and collaborate effectively.
- Commit messages: Use clear and descriptive commit messages when making changes to the dataset. This helps in understanding the purpose and context of each modification. Be concise while providing enough information for others to comprehend the changes made.
- Data dictionary: Create a data dictionary that documents the structure, meaning, and context of each variable in the dataset. Include information such as variable names, descriptions, units of measurement, valid values, and any transformations applied during data cleaning. This ensures that any person working with the dataset understands its intricacies.
- Code documentation: Document the data cleaning steps performed using code comments or markdown cells in your data analysis tool. This helps others understand the rationale behind specific cleaning methods, transformations, or rules implemented. Include explanations for any assumptions made and highlight any potential limitations as well.
- Change log: Maintain a change log that lists all modifications made to the dataset. Include details such as the date and time of the change, the person responsible, the purpose of the change, and any relevant notes. This log acts as a timeline of the data cleaning process and provides a historical record of all changes.
- Collaboration tools: Utilize collaboration tools like Google Docs, project management software, or communication platforms to share the documentation and keep everyone involved in the data cleaning process updated. This fosters transparency and enables effective teamwork.
By creating comprehensive documentation and implementing proper version control, you ensure that the survey data cleaning process remains transparent, reproducible, and well-documented. This not only benefits the current analysis but also aids future researchers and data analysts who may work with the dataset.
Step 8: Finalizing Cleaned Data For Analysis
In Step 8 of the survey data cleaning process, the finalization of cleaned data for analysis takes place. This crucial step ensures that the data is ready for accurate interpretation and insightful analysis.
Conducting A Final Quality Check
Before finalizing the cleaned data for analysis, it is crucial to conduct a final quality check. This step ensures the data is accurate, consistent, and ready for further analysis. Here are some important points to consider:
- Eliminate duplicate entries: Check for any duplicate rows or records in the dataset and remove them to ensure data integrity and avoid skewed analysis results.
- Validate data ranges: Verify that all values fall within their expected ranges, whether numerical or categorical. This helps identify any outliers or errors that might affect the final analysis.
- Address missing values: Determine how to handle missing data points, whether by imputing them with appropriate values or excluding them from the analysis. This step helps minimize biases and errors.
- Cross-compare with original data: Compare the cleaned dataset with the original raw data to ensure that no essential information has been lost or altered during the cleaning process.
- Check for consistency and formatting: Verify that all variables are correctly labeled and formatted, with consistent units and naming conventions. This ensures the coherence and accuracy of the data.
- Perform statistical summaries: Calculate basic statistical measures such as means, medians, and standard deviations to gain a better understanding of the cleaned data’s characteristics. This step helps identify any unusual patterns or discrepancies.
- Check for anomalies: Identify any unusual patterns, outliers, or data entry errors by visualizing the data through graphs or charts. This visual inspection assists in spotting any anomalies that might require further investigation.
Exporting Cleaned Data For Further Analysis And Insights
After conducting the final quality check, it’s time to export the cleaned data for further analysis and deriving insightful conclusions. Here’s what you need to do:
- Select appropriate file format: Choose a file format that suits the analysis techniques and tools you’ll be using. Commonly used formats include CSV, Excel, or JSON.
- Ensure data compatibility: Confirm that the exported data is compatible with the software or programming language you plan to use for analysis. This step ensures a smooth transition from data cleaning to analysis.
- Choose relevant variables: Identify the specific variables or attributes that are of interest for your analysis. This helps streamline the focus and makes the subsequent analysis more efficient.
- Transform and preprocess if necessary: If additional preprocessing or transformation steps are required based on the desired analysis, perform those before exporting the data. This may include feature scaling, binning, or converting variables to appropriate data types.
- Document data cleaning steps: Keep a record of the data cleaning steps taken and any decisions made during the process. This documentation will aid in reproducibility and transparency, ensuring others can understand and replicate your analysis.
- Preserve data privacy and security: Prioritize data privacy and security when exporting the cleaned data by removing any personally identifiable information (PII) or sensitive data. Adhering to privacy regulations is essential to maintain ethical and legal compliance.
- Save and backup the cleaned data: Save the exported cleaned data in a secure location and create backups to ensure data integrity. This enables easy access for future analysis or reference.
By conducting a final quality check and correctly exporting the cleaned data, you can confidently proceed to analyze the data and extract valuable insights for your intended purpose.
Best Practices And Tips For Effective Survey Data Cleaning
Survey data cleaning is essential for accurate analysis and insights. Discover effective best practices and tips to ensure your data is error-free and ready for valuable interpretation.
Cleaning survey data is a crucial step in the research process, ensuring the accuracy and reliability of the collected information. By following best practices and implementing effective data cleaning techniques, you can enhance the quality of your survey data. Here are some tips to help you streamline your data cleaning workflow and prioritize data quality over quantity:
Setting Up A Data Cleaning Workflow
- Establish clear objectives: Clearly define the goals and objectives of your data cleaning process to guide your efforts effectively. This will help you stay focused and ensure that you address all necessary aspects of data quality.
- Identify and handle missing data: Missing data can impact the reliability of your analysis. Identify any missing data points and decide how to handle them – either by imputing values or excluding incomplete records from your analysis.
- Remove duplicate responses: Duplicate responses can skew your findings, so it’s essential to identify and remove them. Use unique identifiers or combinations of variables to identify duplicate entries and decide how to handle them.
- Standardize variables: Consistency in data format is crucial for accurate analysis. Standardize variables by converting them to a consistent format (e.g., date format, capitalization, etc.) To avoid errors and facilitate data comparisons.
- Address outliers: Outliers can significantly impact your analysis, so it’s essential to detect and address them. Determine the criteria for identifying outliers and decide whether to exclude them or explore their potential impact on your results.
- Validate and clean response options: Validate response options to ensure they align with your research objectives. Identify any inconsistent or invalid options and either correct them or assign them to appropriate categories to maintain data integrity.
- Correct data entry errors: Data entry errors are common, but they can lead to inaccurate results. Double-check the accuracy of your data, and correct any entry errors or inconsistencies that you identify.
- Document your cleaning process: Keep a record of all the cleaning steps you perform, including the decisions made and the rationale behind them. This will help ensure transparency, reproducibility, and aid in future data cleaning efforts.
Prioritizing Data Quality Over Quantity
- Thoroughly clean small subsets before scaling up: Start by cleaning a smaller subset of your survey data to test and refine your cleaning techniques. Once you are satisfied with the results, apply the same cleaning process to the entire dataset to save time and ensure consistency.
- Regularly monitor data quality: Continuously monitor the quality of your survey data throughout the data collection period. Detecting data issues early on allows for timely intervention and reduces the effort required during the cleaning stage.
- Collaborate with survey participants: Encourage survey participants to provide accurate and comprehensive responses. Clear instructions, validation checks, and periodic reminders can help improve the quality of the collected data.
- Validate data cleaning outcomes: After cleaning your survey data, validate the outcomes to ensure that the cleaning process has been effective. Check for any remaining anomalies and investigate potential sources of error.
By setting up a robust data cleaning workflow and prioritizing data quality, you can ensure that your survey data is reliable, accurate, and ready for in-depth analysis. Implementing these best practices and tips will save you time and enhance the validity of your research findings.
Frequently Asked Questions For Survey Data Cleaning
What Is Survey Data Cleaning?
Survey data cleaning involves the process of removing errors, inconsistencies, and outliers from collected survey data.
What Are The Steps In Data Cleaning?
Data cleaning involves four key steps: identifying and removing duplicates, handling missing values, correcting inconsistent entries, and standardizing formats.
Why Clean Survey Data?
Cleaning survey data is important to ensure accuracy and reliability of the results.
How Do I Clean Up Survey Data In Excel?
To clean up survey data in Excel, follow these steps: – Remove any duplicate responses. – Check for any missing or incomplete entries. – Use filtering or sorting options to identify and fix any errors or outliers. – Apply data validation techniques to ensure accuracy and consistency in responses.
Conclusion
Data cleaning is an essential step in ensuring the accuracy and reliability of survey results. By removing inconsistencies, errors, and outliers from the data, researchers can draw more meaningful insights and make data-driven decisions confidently. Proper data cleaning techniques, such as detecting and correcting data entry errors, identifying missing values, and addressing data inconsistencies, can help improve the quality of the dataset.
Moreover, the process of data cleaning also involves exploring relationships within the data and identifying patterns or trends that can help uncover valuable insights. It is crucial to maintain transparency and ensure that the data cleaning process is well-documented, as this increases the credibility and reproducibility of research findings.
Overall, investing time and effort into survey data cleaning is a worthwhile endeavor that can significantly enhance the validity and usefulness of research results.
- Survey Service : Boost Your Business with Dynamic Data - January 9, 2024
- Survey Completion: Unlocking Insights and Enhancing Decision-Making - January 9, 2024
- Attitude Survey: Uncover the Hidden Insights - January 9, 2024